程序员的自我修养:链接,装载与库 阅读笔记
我们可以把内存想象成一个巨大的数组,很久以前的程序是直接在物理内存上进行操作的。
- 程序在运行时访问的地址都是物理地址
- 只要程序要求的内存空间不超过物理内存的大小,就不会有问题
- 由于物理内存之间没有隔离,程序很容易遭受恶意攻击或者受bug影响
- 程序的运行地址不确定,因为程序每次需要装入运行时,我们都需要给它从内存中分配一块 足够大的空闲区域
- 内存使用效率低,为了使用A,就必需把整个A都加载进去
解决上面的办法就是引入一个中间层,使用一种间接的地址访问方法。通过物理硬件或者软件(这种方式效率低) 把程序的内存地址映射到某个物理地址。此外还可以做到进程之间的隔离,每个进程看到的都是自己的地址, 而看不到物理地址。
分段:最开始引入的方式就是分段,通过把物理地址和虚拟地址的某一段对应起来,这样就解决了地址隔离的问题,因为 程序A和程序B被映射到了两个不痛得物理空间区域,他们之间没有任何重叠,如果程序A访问了超出它可以访问的范围,硬件 就判定出错。另外还解决了运行地址不确定的问题,程序只需要关心固定的起始地址等,硬件会自动映射到物理内存上。
分页:分段没有解决内存使用效率低的问题,因此引入了分页。分页的基本方法就是把地址空间人为地等分成固定大小 的页,比如4KB。根据程序的局部性原理,每次程序真正使用到的其实只是整个程序中的一小部分,所以分页之后可以只加载 正在使用和可能将要使用的那一部分内存。多余的放在磁盘里。
静态编译和链接:对于C程序,整个过程是:
- 预处理:预编译器把
#include <stdio.h>,#ifdef等包含语句,条件编译等处理,例如#include就把对应的代码插进去。主要处理规则如下:- 将所有的
#define删除,并且展开所有的宏定义 - 处理所有条件预编译指令,例如
#if,#ifdef等 - 处理
#include将被包含的文件插入到对应的位置,这个过程是递归的 - 删除所有的注释
//和/**/ - 添加行号和文件名标识,以便编译时编译器产生调试用的行号信息等
- 保留所有的
#pragma编译器指令,因为编译器需要它们 经过预编译之后的.i文件不包含任何宏定义,因为所有的宏已经被展开,并且包含的文件也已经被插入到.i文件中。
- 将所有的
- 编译:通过一系列的此法分析,语法分析,语法优化等步骤之后,产生汇编代码
- 汇编:汇编器将上一步产生的汇编代码转换成机器可以执行的机器指令,每一个汇编语句几乎都对应一条机器指令
- 链接:将汇编器产生的机器码进一步处理,将其中的各种变量替换成对应的地址。
- 预处理:预编译器把
目标文件:编译器编译源代码之后产生的文件叫做目标文件。目标文件基本上和可执行文件的格式一致, 只是在文件结构上稍有不同。Linux是ELF: Executable Linkable Format,Windows下是PE: Portable Executable, 他们都是COFF: Common file format格式的变种。
Section, Segment: 目标文件中,按照不同的属性,将内容分开存储,其中各部分就叫节(Section)或者段(Segment):
- 编译后产生的机器指令一般放在代码段(code section),代码段常见的名字有
.code或者.text - 全局变量和局部静态变量静量常放在数据段(data section),数据段常见的名字叫
.data - 未初始化的全局变量和局部静态变量一般都放在bss段里,其默认值都是0.bss段只是为未初始化的全局变量和静态变量 预留位置,并没有内容,因为他们的值都是0,所以没有必要占用空间,他们并不占据空间。
- 为什么要将代码和数据分开?因为当该程序有多个副本时,可以共享同一个段
- 编译后产生的机器指令一般放在代码段(code section),代码段常见的名字有
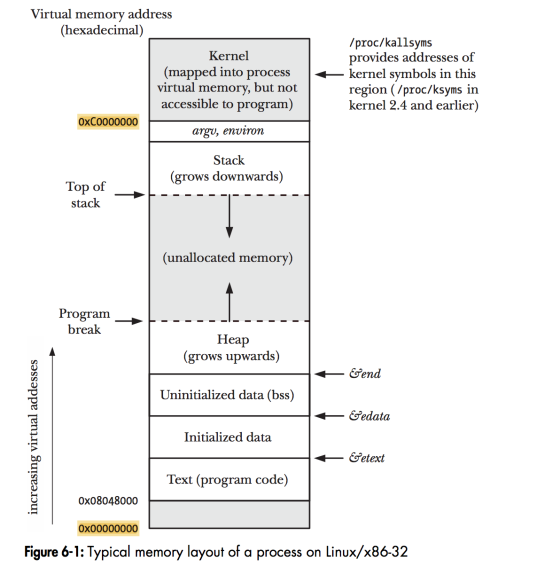
Linux下的内存布局:

 邮件 订阅
邮件 订阅
 RSS 订阅
RSS 订阅
 Web开发简介系列
Web开发简介系列
 数据结构的实际使用
数据结构的实际使用
 Golang 简明教程
Golang 简明教程
 Python 教程
Python 教程