SQLAlchemy简明教程
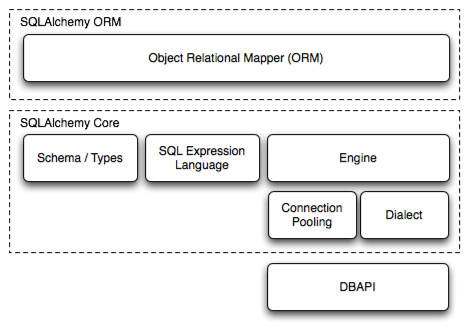
SQLAlchemy是Python中常用的一个ORM,SQLAlchemy分成三部分:
- ORM,就是我们用类来表示数据库schema的那部分
- SQLAlchemy Core,就是一些基础的操作,例如
update,insert等等,也可以直接使用这部分来进行操作,但是它们写起来没有ORM那么自然 - DBAPI,这部分就是数据库驱动
它们的关系如下(图片来自官网):
我们先来看看一个简单的例子:
import contextlib
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
from sqlalchemy import (
create_engine,
Column,
Integer,
DateTime,
String,
)
from config import config # config模块里有自己写的配置,我们可以换成别的,注意下面用到config的地方也要一起换
engine = create_engine(
config.SQLALCHEMY_DATABASE_URI, # SQLAlchemy 数据库连接串,格式见下面
echo=bool(config.SQLALCHEMY_ECHO), # 是不是要把所执行的SQL打印出来,一般用于调试
pool_size=int(config.SQLALCHEMY_POOL_SIZE), # 连接池大小
max_overflow=int(config.SQLALCHEMY_POOL_MAX_SIZE), # 连接池最大的大小
pool_recycle=int(config.SQLALCHEMY_POOL_RECYCLE), # 多久时间主动回收连接,见下注释
)
Session = sessionmaker(bind=engine)
Base = declarative_base(engine)
class BaseMixin:
"""model的基类,所有model都必须继承"""
id = Column(Integer, primary_key=True)
created_at = Column(DateTime, nullable=False, default=datetime.datetime.now)
updated_at = Column(DateTime, nullable=False, default=datetime.datetime.now, onupdate=datetime.datetime.now, index=True)
deleted_at = Column(DateTime) # 可以为空, 如果非空, 则为软删
@contextlib.contextmanager
def get_session():
s = Session()
try:
yield s
s.commit()
except Exception as e:
s.rollback()
raise e
finally:
s.close()
class User(Base, BaseMixin):
__tablename__ = "user"
Name = Column(String(36), nullable=False)
Phone = Column(String(36), nullable=False, unique=True)
我们注意上面的几点:
- pool_recycle,设置主动回收连接的时长,如果不设置,那么可能会遇到数据库主动断开连接的问题,例如MySQL通常会为连接设置
最大生命周期为八小时,如果没有通信,那么就会断开连接。因此不设置此选项可能就会遇到
MySQL has gone away的报错。 - engine,engine是SQLAlchemy 中位于数据库驱动之上的一个抽象概念,它适配了各种数据库驱动,提供了连接池等功能。其用法就是
如上面例子中,
engine = create_engine(<数据库连接串>),数据库连接串的格式是dialect+driver://username:password@host:port/database?参数这样的,dialect 可以是mysql,postgresql,oracle,mssql,sqlite,后面的 driver 是驱动,比如MySQL的驱动pymysql, 如果不填写,就使用默认驱动。再往后就是用户名、密码、地址、端口、数据库、连接参数了,我们来看几个例子:- MySQL:
engine = create_engine('mysql+pymysql://scott:tiger@localhost/foo?charset=utf8mb4') - PostgreSQL:
engine = create_engine('postgresql+psycopg2://scott:tiger@localhost/mydatabase') - Oracle:
engine = create_engine('oracle+cx_oracle://scott:tiger@tnsname') - MS SQL:
engine = create_engine('mssql+pymssql://scott:tiger@hostname:port/dbname') - SQLite:
engine = create_engine('sqlite:////absolute/path/to/foo.db') - 详见:https://docs.sqlalchemy.org/en/13/core/engines.html
- MySQL:
Session,Session的意思就是会话,也就是说,是一个逻辑组织的概念,因此,这需要靠你的业务逻辑来划分哪些操作使用同一个Session, 哪些操作又划分为不同的业务操作,详见 这里。 举个简单的例子,以web应用为例,一个请求里共用一个Session就是一个好的例子,一个异步任务执行过程中使用一个Session也是一个例子。 但是注意,不能直接使用Session,而是使用Session的实例,借助上面的代码,我们可以直接这样写:
with get_session() as s: print(s.query(User).first())Base,Base是ORM中的一个基类,通过集成Base,我们才能方便的使用一些基本的查询,例如
s.query(User).filter_by(User.name="nick").first()。BaseMixin,BaseMixin是我自己定义的一些通用的表结构,通过Mixin的方式集成到类里,比如上面的定义,我们常见的表结构里,都会有 ID、创建时间,更新时间,软删除标志等等,我们把它作为一个独立的类,这样通过继承即可获得相关表属性,省得重复写多次。
表的设计
表的设计通常就如 User 表一样:
class User(Base, BaseMixin):
__tablename__ = "user"
Name = Column(String(36), nullable=False)
Phone = Column(String(36), nullable=False, unique=True)
首先使用 __tablename__ 自定义表名,接着写各个表中的属性,也就是对应在数据库表中的列(column),常见的类型有:
$ egrep '^class ' ~/.pyenv/versions/3.6.0/lib/python3.6/site-packages/sqlalchemy/sql/sqltypes.py
class _LookupExpressionAdapter(object):
class Concatenable(object):
class Indexable(object):
class String(Concatenable, TypeEngine):
class Text(String):
class Unicode(String):
class UnicodeText(Text):
class Integer(_LookupExpressionAdapter, TypeEngine):
class SmallInteger(Integer):
class BigInteger(Integer):
class Numeric(_LookupExpressionAdapter, TypeEngine):
class Float(Numeric):
class DateTime(_LookupExpressionAdapter, TypeEngine):
class Date(_LookupExpressionAdapter, TypeEngine):
class Time(_LookupExpressionAdapter, TypeEngine):
class _Binary(TypeEngine):
class LargeBinary(_Binary):
class Binary(LargeBinary):
class SchemaType(SchemaEventTarget):
class Enum(Emulated, String, SchemaType):
class PickleType(TypeDecorator):
class Boolean(Emulated, TypeEngine, SchemaType):
class _AbstractInterval(_LookupExpressionAdapter, TypeEngine):
class Interval(Emulated, _AbstractInterval, TypeDecorator):
class JSON(Indexable, TypeEngine):
class ARRAY(SchemaEventTarget, Indexable, Concatenable, TypeEngine):
class REAL(Float):
class FLOAT(Float):
class NUMERIC(Numeric):
class DECIMAL(Numeric):
class INTEGER(Integer):
class SMALLINT(SmallInteger):
class BIGINT(BigInteger):
class TIMESTAMP(DateTime):
class DATETIME(DateTime):
class DATE(Date):
class TIME(Time):
class TEXT(Text):
class CLOB(Text):
class VARCHAR(String):
class NVARCHAR(Unicode):
class CHAR(String):
class NCHAR(Unicode):
class BLOB(LargeBinary):
class BINARY(_Binary):
class VARBINARY(_Binary):
class BOOLEAN(Boolean):
class NullType(TypeEngine):
class MatchType(Boolean):
常见操作
我们来看看使用SQLAlchemy完成常见的操作,例如增删查改:
常见查询操作
SELECT * FROM user应该这样写:with get_session() as s: print(s.query(User).all())SELECT * FROM user WHERE name='nick'应该这样写:with get_session() as s: print(s.query(User).filter_by(User.name='nick').all()) print(s.query(User).filter(User.name == 'nick').all()) # 这样写是等同效果的SELECT * FROM user WHERE name='nick' LIMIT 1应该这样写:with get_session() as s: print(s.query(User).filter_by(User.name='nick').first())
如果需要加判定,例如确保只有一条数据,那就把 first() 替换为 one(),如果确保一行或者没有,那就写 one_or_none()。
SELECT * FROM user ORDER BY id DESC LIMIT 1应该这样写:with get_session() as s: print(s.query(User).order_by(User.id.desc()).first())SELECT * FROM user ORDER BY id DESC LIMIT 1 OFFSET 20应该这样写:with get_session() as s: print(s.query(User).order_by(User.id.desc()).offset(20).first())
常见删除操作
DELETE FROM user应该这样写:with get_session() as s: s.query(User).delete()DELETE FROM user WHERE name='nick':with get_session() as s: s.query(User).filter_by(User.name='nick').delete()DELETE FROM user WHERE name='nick' LIMIT 1:with get_session() as s: s.query(User).filter_by(User.name='nick').limit(1).delete()
更新语句
UPDATE user SET name='nick':with get_session() as s: s.query(User).update({'name': 'nick'})UPDATE user SET name='nick' WHERE id=1:with get_session() as s: s.query(User).filter_by(User.id=1).update({'name': 'nick'})
也可以通过更改实例的属性,然后提交:
with get_session() as s:
user = s.query(User).filter_by(User.id=1).one()
user.name = 'nick'
s.commit()
插入语句
这个就简单了,实例化对象,然后 session.add,最后提交:
with get_session() as s:
user = User()
s.add(user)
s.commit()
连表
SQLAlchemy 中可以直接使用join语句:
with get_session() as s:
s.query(Customer).join(Invoice).filter(Invoice.amount == 8500)
可以是这么几种写法:
query.join(Address, User.id==Address.user_id) # explicit condition
query.join(User.addresses) # specify relationship from left to right
query.join(Address, User.addresses) # same, with explicit target
query.join('addresses') # same, using a string
数据库migration
我们使用alembic来做数据库migration,首先安装:
$ pip install alembic
$ alembic init alembic # 此处 alembic init 后接的是保存migration的文件夹名称
然后我们要修改 alembic/env.py (假设你设置的保存migration的文件夹名称就是 alembic),将对应部分修改成如下:
config.set_main_option(
'sqlalchemy.url', config.SQLALCHEMY_DATABASE_URI
)
target_metadata = Base.metadata # 从任意一个我们的model可以拿到总的Base
engine = target_metadata.bind
因为SQLAlchemy会把表的信息存储在 metadata 里,而我们都继承了 Base,因此可以
通过 Base.metadata 来拿到所有表的信息,这样子alembic才能够拿到表的结构,然后和
数据库进行对比,生成migration脚本:
$ alembic revision --autogenerate -m '本次migration的信息,相当于git提交时的评论'
总结
这一篇中我们看了如何使用SQLAlchemy来进行常见的操作,我们首先从如何定义表开始,接着我们注意看了常见的SQL操作对应的 SQLAlchemy操作是怎样的,最后我们看了以下alembic应该怎么配置才能自动生成migration脚本。
参考资料:

 邮件 订阅
邮件 订阅
 RSS 订阅
RSS 订阅
 Web开发简介系列
Web开发简介系列
 数据结构的实际使用
数据结构的实际使用
 Golang 简明教程
Golang 简明教程
 Python 教程
Python 教程